Site menu:
Leseverständnis - Was ist das?
Gliederung

- Komponenten des Leseverständnisses
- Prozesse auf Wortebene
- Prozesse auf Satzebene
- Prozesse auf Textebene
- Literatur
Weiterführende Informationen
Die hier dargestellte theoretische Einführung in das Thema Leseverständnis stammt aus dem Handbuch von ELFE II (Kapitel 4). Sie bildete die Grundlage für die Konstruktion des ELFE II Leseverständnistests.
Zitierfähige Quelle für den Text: Lenhard, W., Lenhard, A. & Schneider, W. (2017). Ein Leseverständnistest für Erst- bis Siebtklässler II (ELFE II). Göttingen: Hogrefe. (Achtung: Die Abbildungen sind im Vergleich zum ELFE II-Manual leicht verändert.)
Sollten Sie an weiteren Publikationen und Informationen interessiert sein, so empfehlen wir auch das Buch
 Lenhard, W. (2013). Leseverständnis und Lesekompetenz: Grundlagen - Diagnostik - Förderung. Stuttgart: Kohlhammer.
Lenhard, W. (2013). Leseverständnis und Lesekompetenz: Grundlagen - Diagnostik - Förderung. Stuttgart: Kohlhammer.
"Die Schriftsprache ist eine der faszinierendsten Errungenschaften der Menschheit. Der Prozess des Verstehens beim
Lesen ist sehr komplex und wird von vielen Einflussfaktoren bestimmt. Im Buch werden diese Faktoren, ihre Entwicklung und ihr Zusammenspiel systematisch erarbeitet.
Hierdurch eröffnet sich eine Perspektive auf die Frage, an welchen Punkten Diagnostik und Förderung ansetzen können. Dieses Buch bietet dem Leser einen Einblick in
Theorien und Modelle und zeigt aktuelle Forschungsergebnisse und die Entwicklung im deutschsprachigen Raum seit der ersten PISA-Untersuchung auf. Darüber hinaus beleuchtet es
die Frage, wo die besonderen Bedürfnisse schwacher Leser liegen, schildert Diagnosemöglichkeiten und geht auf systematische und evidenzbasierte Fördermöglichkeiten ein."
Komponenten des Leseverständnisses
Vergleicht man die beiden Schriftsprachkomponenten Lesen und Schreiben miteinander, so drängt sich leicht die Vorstellung auf, dass es sich beim Lesen um eine eher passiv-rezeptive, beim Schreiben dagegen um eine aktiv-produktive Tätigkeit handelt. Im Gegensatz zu dieser intuitiven Alltagsvorstellung gehen allerdings die kognitive Psychologie und die experimentelle Leseforschung davon aus, dass das Lesen (bzw. Sprachrezeption im Allgemeinen) einen hochgradig aktiven Prozess der Auseinandersetzung mit den jeweiligen Inhalten darstellt (Klicpera & Gasteiger-Klicpera, 1995, S. 133; Artelt, Stanat, Schneider & Schiefele, 2001; Schneider, 2016). Die Aufgabe und gleichzeitig das Ziel des Lesers besteht in der Regel darin, die Information, die vom Schreiber in einem Text enkodiert wurde, zu dekodieren, also zu entschlüsseln (Christmann & Groeben, 1999). Dieser Prozess der Rekonstruktion besteht aber nicht nur darin, die Bedeutung der einzelnen Wörter zu dechiffrieren, sondern die Wortbedeutungen mit den umgebenden Informationen - den anderen Wörtern, Sätzen und Textteilen - in eine sinnvolle Verbindung zu setzten. Die entnommenen Informationen werden dabei - ggf. mithilfe von strategischem Verhalten - auf der Basis des individuellen Vorwissens interpretiert und führen unter Umständen zu weit über den tatsächlichen Text hinausgehenden Schlussfolgerungen (vgl. Cromley & Azevedo, 2007).
Im Folgenden werden die für das Verstehen eines Textes erforderlichen Verarbeitungsschritte beleuchtet, wobei zwischen hierarchieniederen Prozessen auf Wort- und Satzebene und hierarchiehohen Prozessen auf Textebene unterschieden wird. Beim Wechselspiel dieser verschiedenen Komponenten greifen zahlreiche Teilprozesse ineinander, bis schließlich aus der Wortoberfläche eines Textes ein geistiges Abbild des Inhalts entstanden ist. Es existieren viele Modelle, die diesen Prozess zu beschreiben versuchen. Dabei fokussieren die einzelnen Modelle meist auf bestimmte Aspekte (vgl. W. Lenhard & Artelt, 2009). Die Theorie der verbalen Effizienz (Perfetti, 1989) geht beispielsweise davon aus, dass das Leseverstehen vor allem von Prozessen auf Ebene der Worterkennung abhängt. Je sicherer und schneller ein Mensch Wörter erkennt, desto besser ist gemäß dieser Theorie das Leseverständnis. Einen etwas weiteren Blickwinkel nimmt der Simple-View-of-Reading (Gough & Tunmer, 1986) ein, demzufolge das Leseverstehen von der Worterkennung und dem Hörverstehen bzw. den allgemeinen Fähigkeiten zur Sprachrezeption abhängt. Die Leseflüssigkeit stellt in diesem Modell lediglich einen limitierenden Faktor dar. Interaktionistische Ansätze wiederum betonen, dass basale Prozesse (z. B. die Worterkennung) und hierarchiehohe Prozesse (z. B. das Herstellen eines globalen Zusammenhangs zwischen Wörtern bzw. Sätzen) stark ineinandergreifen und sich gegenseitig beeinflussen (vgl. Christmann & Groeben, 1999; Richter & Christmann, 2002). Die Frage nach der Gültigkeit der einzelnen Modelle lässt sich nicht ohne weitere Vorannahmen beantworten, da die Bedeutung einzelner Teilprozesse und deren Zusammenspiel bei der konkreten Lesetätigkeit auch vom Entwicklungsstand des Lesers bzw. der Leserin, dem Leseanlass und den Texteigenschaften abhängen. Darüber hinaus hängt die Validierbarkeit einzelner Modelle auch immer davon ab, mit welchen Messinstrumenten bestimmte Teilprozesse erfasst werden (vgl. z. B. Keenan, Betjemann & Olson, 2008).
Unabhängig von der unterschiedlichen Bedeutung, die den einzelnen Komponenten in den verschiedenen Modellen zugewiesen wird, besteht allerdings relativ hoher Konsens darüber, welche wesentlichen Prozesse überhaupt beim Lesen ablaufen. Auf niedriger Hierarchieebene lassen sich all jene Aspekte subsumieren, die damit zu tun haben, die Wörter und die Syntax zu entschlüsseln. Hierzu gehören beispielsweise die schnelle und zuverlässige Erkennung von Schriftzeichen, Buchstabengruppen, Wortbestandteilen und ganzen Wörtern, die Extraktion von Bedeutungseinheiten (sog. Propositionen) aus Sätzen, die Rekonstruktion der syntaktischen Tiefenstruktur eines Satzes sowie die Verknüpfung von Sätzen und Satzteilen über sog. Kohäsionsmittel (vgl. W. Lenhard, 2013, Kap. 2.1). Auf hoher Hierarchieebene werden diese Bedeutungen unter Verwendung des eigenen bereichsspezifischen Vorwissens in eine übergeordnete Makrostruktur oder eine Rahmenhandlung eingefügt, ein Prozess, der als globale Kohärenzbildung bezeichnet wird. Dabei spielen die Selbstregulation (d.h. die Fähigkeit, den eigenen Verständnisprozess zu überwachen) und die Inferenzbildung (d. h. das Ziehen von über den Text hinausgehenden Schlussfolgerungen) eine große Rolle. Aufbauend auf diesen Prozessen entsteht eine mentale Repräsentation, das sog. Situationsmodell, welches eine stark verdichtete, durch eigenes Vorwissen und Schlussfolgerungen angereicherte und in eigenen Worten reproduzierbare Zusammenfassung des Textinhaltes darstellt. Damit die verschiedenen Teilprozesse messtechnisch voneinander getrennt werden können, bietet sich bei der psychometrischen Erfassung des Leseverständnisses eine differenzierte Betrachtung von Wort-, Satz- und Textebene an. Seit der Veröffentlichung der ersten Fassung dieses Tests (W. Lenhard & Schneider, 2006) wurden im internationalen Bereich etliche Studien publiziert, die diese Aufteilung stützen (z. B. Ahmed, Wagner & Lopez, 2014; Klauda & Guthrie, 2008). Sie stellt deshalb die theoretische Grundlage für die Konstruktion des Testverfahrens dar. Die einzelnen Teilprozesse werden in den folgenden Abschnitten auf der Basis dieser Aufteilung näher spezifiziert und beschrieben.
Prozesse auf Wortebene
Modelle der visuellen Worterkennung
Das Erkennen der Bedeutung einzelner Wörter spielt für das Hauptziel des Lesens - nämlich das inhaltliche Verständnis des schriftlichen Materials - eine zentrale Rolle. Dies wird auch darin deutlich, dass beim automatisierten Lesen während des Lesevorgangs in der Regel immer ein einzelnes Wort für eine gewisse Zeit fixiert und anschließend mittels einer Sakkade (= Blicksprung) zum nächsten Wort gesprungen wird. Der Lesevorgang ist also zumindest beim geübten Leser im Wesentlichen ein Lesen Wort für Wort (Klicpera & Gasteiger-Klicpera, 1995).
Ein Leseanfänger kann Wörter allerdings noch nicht im Ganzen erfassen. Sein Fokus liegt (zumindest in relativ lauttreuen Schriftsprachen wie dem Deutschen) zunächst nur auf einzelnen
Buchstaben oder Buchstabengruppen, die einen bestimmten Laut repräsentieren (z. B. "sch"). Bereits die Identifikation dieser kleinsten bedeutungsunterscheidenden
 Einheiten der Sprache,
also der Grapheme, beinhaltet beim nicht automatisierten Lesen eine ganze Reihe an Schwierigkeiten: Zunächst müssen die einzelnen Schriftzeichen unabhängig von Form, Farbe und dem verwendeten
Schriftsatz identifiziert und einer bestimmten Buchstabenklasse zugeordnet werden (siehe Abb.1). Aufgrund der relativ komplexen Silbenstruktur des Deutschen (vgl. z. B. P. Marx, 2007, S. 24; Seymour,
Aro & Erskine, 2003) kann aber selbst beim Erkennen der Buchstabenklassen die
Identifikation der Grapheme schwierig werden. So stellt beispielsweise die Buchstabengruppe "sch" im Wort "Engelschöre" nicht das Graphem [sch], sondern eben die zwei Grapheme [s] und [ch] dar,
die durch eine Silbengrenze voneinander abgetrennt sind.
Einheiten der Sprache,
also der Grapheme, beinhaltet beim nicht automatisierten Lesen eine ganze Reihe an Schwierigkeiten: Zunächst müssen die einzelnen Schriftzeichen unabhängig von Form, Farbe und dem verwendeten
Schriftsatz identifiziert und einer bestimmten Buchstabenklasse zugeordnet werden (siehe Abb.1). Aufgrund der relativ komplexen Silbenstruktur des Deutschen (vgl. z. B. P. Marx, 2007, S. 24; Seymour,
Aro & Erskine, 2003) kann aber selbst beim Erkennen der Buchstabenklassen die
Identifikation der Grapheme schwierig werden. So stellt beispielsweise die Buchstabengruppe "sch" im Wort "Engelschöre" nicht das Graphem [sch], sondern eben die zwei Grapheme [s] und [ch] dar,
die durch eine Silbengrenze voneinander abgetrennt sind.  Bisweilen spielt also bereits für die
Identifikation von Graphemen oder typischen Graphemgruppen (z. B. Präfixen und Suffixen)
das Erkennen von Silben- oder Wortgrenzen eine Rolle. Den Graphemen müssen sodann Laute bzw. Lautklassen zugeordnet werden, wobei sich sowohl die Position eines Schriftzeichens innerhalb einer
Silbe als auch innerhalb des gesamten Wortes auf die lautliche Realisation auswirkt. Beispielsweise werden die beiden "e"s in "senden" unterschiedlich artikuliert, obwohl sie beide innerhalb
ihrer jeweiligen Silbe die gleiche Position innehaben (siehe Abb. 2). Wie man hieran leicht sehen kann, gibt es also auch im Deutschen keine ganz eindeutige Zuordnung von Lauten zu
Schriftzeichen.
Bisweilen spielt also bereits für die
Identifikation von Graphemen oder typischen Graphemgruppen (z. B. Präfixen und Suffixen)
das Erkennen von Silben- oder Wortgrenzen eine Rolle. Den Graphemen müssen sodann Laute bzw. Lautklassen zugeordnet werden, wobei sich sowohl die Position eines Schriftzeichens innerhalb einer
Silbe als auch innerhalb des gesamten Wortes auf die lautliche Realisation auswirkt. Beispielsweise werden die beiden "e"s in "senden" unterschiedlich artikuliert, obwohl sie beide innerhalb
ihrer jeweiligen Silbe die gleiche Position innehaben (siehe Abb. 2). Wie man hieran leicht sehen kann, gibt es also auch im Deutschen keine ganz eindeutige Zuordnung von Lauten zu
Schriftzeichen.
Wenn der Leseprozess noch nicht automatisiert ist, müssen die identifizierten Laute in der richtigen Reihenfolge in der phonologischen Schleife des Arbeitsgedächtnisses abgelegt und anschließend zu einer Lautfolge zusammengefügt werden. Die phonologische Struktur eines Wortes wird also mittels phonologischer Rekodierung der Grapheme seriell rekonstruiert. Die ist ein Prozess, der hohe Ressourcen des phonologischen Arbeitsgedächtnisses beansprucht. Nur wenn er gelingt, kann der generierten Lautsequenz schließlich auch ein Wort aus dem semantischen Lexikon zugeordnet werden, d. h. nur dann kann das Gelesene auch verstanden (dekodiert) werden. Angesichts dieser Anforderungen verwundert es nicht, dass verstehendes Lesen durch schlecht ausgeprägte basale Funktionen stark limitiert werden kann (vgl. z. B. Brandenburg et al., 2013; Fischbach, Preßler & Hasselhorn, 2012; Mähler & Schuchardt, 2012), andererseits aber umso einfacher und schneller bewältigt wird, je stärker automatisiert die beteiligten Leseprozesse sind (vgl. z. B. Denton et al., 2011; Kim & Wagner, 2015; Silverman, Speece, Harring & Ritchey, 2013). Diese Automatisierung wird bei deutschsprachigen Kindern in der Regel bereits innerhalb des ersten Schuljahres deutlich vorangetrieben, wodurch die Entwicklung der schriftsprachlichen Fähigkeiten sehr stark an Fahrt aufnimmt. Wörter müssen dann nicht mehr mühsam entschlüsselt werden, sondern sie können unmittelbar den Bedeutungseinheiten und Lautbildern aus dem semantischen Gedächtnis zugeordnet werden. Dem geübten Leser stehen schließlich beide Strategien zur Verfügung: die direkte, ganzheitliche (d. h. automatisierte) Worterkennung und das indirekte Erlesen von Wörtern Buchstabe für Buchstabe.
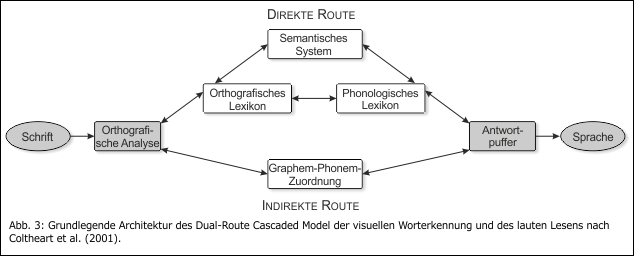
Die Unterscheidung in diese beiden Verarbeitungspfade ist zugleich der Grundgedanke der vielleicht prominentesten Theorie der Worterkennung, der sog. Zwei-Wege-Theorie
(Dual Route Theory nach Coltheart & Rastle, 1994 bzw. Dual-Route Cascaded Model nach Coltheart, Rastle, Perry, Langdon & Ziegler, 2001; siehe Abb. 3). Sie steht nicht nur in Einklang mit
zahlreichen neurologischen Erkenntnissen aus dem Bereich der erworbenen Dyslexie, sondern hat auch die Forschung nach Subgruppen der Lese-Rechtschreibstörung wesentlich befruchtet (siehe z. B.
Morris et al., 1998; Stanovich, Siegel, Gottardo, Chiappe & Sidhu, 1997; Fletcher et al. 1997). Zudem lassen sich die beiden Mechanismen beim geübten Leser während des Leseprozesses über
bildgebende Verfahren nachweisen (vgl. Dehaene, 2010, S. 116 f.): Beide Routen manifestieren sich in voneinander unabhängigen neuronalen Netzwerken unseres Gehirns und werden beim geübten
Leser parallel aktiviert. Da die automatisierte Erkennung ganzer Wörter wesentlich schneller erfolgt als die Rekodierung der Einzellaute, kommt beim geübten Leser in der Regel allerdings die
direkte Route zum Zug. Nur bei Wörtern, die nicht im semantischen Lexikon vertreten sind, wird die zweite, indirekte Route gewählt.
Einfluss von Bedeutung und Kontext auf die Worterkennung
Zweifellos stellt die visuelle Worterkennung eine Grundlage für das verstehende Lesen dar, jedoch kann keineswegs von einer strengen Abfolge vom Einfachen zum Komplexen ausgegangen werden. Dies zeigt sich darin, dass auch das Lesen von Wörtern und Zeichen vom Kontext abhängt und somit hierarchiehöhere Prozesse auf die Worterkennung zurückwirken. In der experimentellen Forschung lässt sich Kontextabhängigkeit beim Lesen von Wörtern und Zeichen folgendermaßen demonstrieren: Bietet man Versuchspersonen Pseudowörter (d. h. wortähnliche, aber sinnlose Zeichenketten) dar und weist einem Teil dieser Pseudowörter willkürlich Bedeutungen zu, dann können diese "bedeutungshaltigen" Pseudowörter schneller gelesen werden als die sinnlosen. Gleichermaßen kann ein und dasselbe Schriftzeichen schneller gelesen werden, wenn es innerhalb eines sinnvollen Wortes vorkommt, im Vergleich zu einer isolierten Darbietung oder einer Einbettung in sinnlose Zeichenketten - ein Effekt, der als Wortüberlegenheitseffekt bezeichnet wird und erstmals von McKeen Cattell (1886; siehe auch Balota, 1990) beschrieben wurde. Die Einbettung von Schriftzeichen in sinnvolle oder bedeutungstragende Wörter wirkt sich folglich auf die Geschwindigkeit der Erkennung der einzelnen Grapheme aus.
Auch bezüglich der Einbettung von Wörtern in Sätze lassen sich ähnliche Effekte zeigen: Der Kontext kann von den Lesenden zur Korrektur bzw. Vermeidung von Lesefehlern herangezogen werden und gleichzeitig wird die Worterkennung durch Voraktivierung ähnlicher Bedeutungsinhalte beschleunigt (Oakhill & Garnham, 1988, S. 84). Ein illustres Beispiel bieten die beiden folgenden Sätze: "Die Soldaten blieben noch lange in der Wachstube." vs. "Er wollte das Leder einwachsen, musste aber feststellen, dass die Wachstube leer war." Die Bedeutung und Aussprache des Wortes "Wachstube" kann beim Lesen in diesem Beispiel sogar nur aus dem Kontext erschlossen werden. Insbesondere erfahrenen Lesern gelingt es leichter, den Kontext heranzuziehen, um Vorhersagen über das nächste auftretende Wort zu machen sowie Lesefehler zu korrigieren. Die Einbettung von Wörtern in einen kongruenten Kontext führt im Vergleich zur isolierten Darbietung von Wörtern ohne jeglichen Kontext zur Beschleunigung der Worterkennung. Inkongruenter Kontext führt hingegen v. a. bei Kindern zur Verlangsamung der Erkennungsgeschwindigkeit. Zusammenfassend lässt sich also sagen, dass beim Lesen eine ständige Interaktion zwischen hierarchiehohen und hierarchieniederen Prozessen stattfindet, die sich bereits auf der Ebene des Wortverständnisses bemerkbar macht.
Prozesse auf Satzebene
Ein Schlüssel zum Verständnis ganzer Sätze steckt in der Syntax, d. h. in der Systematik der Wortreihenfolge innerhalb von Sätzen. Die Sprachforschung unterscheidet hier grundsätzlich zwischen der Oberflächenstruktur und der Tiefenstruktur. Unter der Oberflächenstruktur versteht man die unmittelbar beobachtbare Abfolge von Wörtern. Ein Wort steht aber nicht nur mit dem jeweils vorausgehenden und nachfolgenden Wort in Beziehung, sondern es existieren charakteristische Beziehungen zwischen Wörtern oder Gruppen von Wörtern, die unter Umständen innerhalb des Satzes auch weit voneinander entfernt stehen können. Darüber hinaus sind die Beziehungen bisweilen stark ineinander verschachtelt. Man bezeichnet diese Beziehungen zwischen Wörtern und Wortgruppen als Tiefenstruktur des Satzes. Erst wenn sie entschlüsselt ist, kann der Satz auch verstanden werden (Christmann & Groeben, 1999; Richter & Christmann, 2002). Das Entschlüsseln der einzelnen Wortbedeutungen gewährleistet also noch lange nicht das Verstehen des gesamten Satzes. Auch kann sich die Bedeutung der einzelnen Wörter durch die Stellung im Satz oder das Auftreten anderer Wörter verändern. Man beachte beispielsweise, wie sich die Bedeutung des Wortes "Bank" in den folgenden zwei Sätzen nur dadurch verändert, dass das Wort "sich" hinzukommt: "Weil die Anforderung für ihn zu hoch war, setzte er auf die Bank." vs. "Weil die Anforderung für ihn zu hoch war, setzte er sich auf die Bank."
Das Entschlüsseln der Tiefenstruktur eines Satzes wird in der Linguistik als Parsing bezeichnet. Hierdurch entsteht eine propositionale Struktur des Satzes, d. h. dass nun die Wortgruppen und deren Beziehungen - nicht mehr die einzelnen Wörter - die grundlegenden Informationseinheiten darstellen. Der mentale Aufbau dieser Bedeutungsstruktur wird als lokale Kohärenzbildung bezeichnet (vgl. W. Lenhard, 2013, Kap. 2.1.1). Die Schwierigkeit beim Parsing besteht darin, dass die Struktur des Satzes bisweilen erst endgültig geklärt werden kann, wenn der Satz vollständig gelesen wurde. In einem Satz, der mit den Worten "Die Lehrerin schlug..." beginnt, würden die meisten Leser den Teil "Die Lehrerin" vermutlich zunächst als Subjekt des Satzes identifizieren. Dies wäre beispielsweise dann richtig, wenn der Satz mit "...das Buch auf." enden würde. Eine ganz andere Wendung nimmt der Satz hingegen, wenn er mit den folgenden Worten endet "...der kleinste aus der Rockergruppe, während sein kräftiger Kumpel sich den Schuldirektor vornahm." Dass sich eine Vermutung über die Bedeutung eines Satzteils beim weiteren Lesen als falsch herausstellt, bezeichnet man auch als Holzweg- oder Sackgasseneffekt (engl. garden path effect; vgl. Sanz, Laka & Tanenhaus, 2013). Dieser Effekt zeigt gleichzeitig auf, welche hohen kognitiven Anforderungen beim Satzlesen bisweilen bewältigt werden müssen. Schließlich erfordert das Parsing nicht nur, dass die einzelnen gelesenen Wörter in der phonologischen Schleife gespeichert werden, sondern es müssen bereits während des Lesens Hypothesen über die propositionale Struktur des Satzes gebildet und beim Weiterlesen unter Umständen wieder revidiert werden - ein Prozess, der eine hohe Belastung für die exekutiven Funktionen des Arbeitsgedächtnisses darstellt. Es verwundert deshalb nicht, dass Kinder mit selektiven Defiziten im Leseverständnis (aber nicht in der Rechtschreibung) im Schnitt starke Minderleistungen in diesen kognitiven Funktionen aufweisen (Brandenburg et al., 2013).
In Übereinstimmung mit dem weiter oben bereits erwähnten Simple-View-of-Reading (Gough & Tunmer, 1986) zeigen viele empirische Untersuchungen, dass die Fähigkeit zum Entschlüsseln der Struktur eines Satzes und zur Bildung lokaler Kohärenzen sowohl einen wichtigen Beitrag zum Leseverständnis als auch zum Sprachverständnis generell liefert: Einerseits sind Kinder mit gutem Sprachverständnis leichter in der Lage, syntaktische Fehler in grammatikalisch komplexen Sätzen zu erkennen (Waltzman & Cairns, 2000). Andererseits haben die syntaktischen Fähigkeiten darüber hinaus einen deutlichen Einfluss auf das Leseverständnis (Ennemoser, Marx, Weber & Schneider, 2012), wie insbesondere bei Kindern mit Migrationshintergrund gezeigt werden kann (Martohardjono et al., 2005; Gabriele, Troseth, Martohardjono & Otheguy, 2009). Trotzdem greift der Simple-View-of-Reading aus verschiedenen Gründen bzw. an verschiedenen Stellen zu kurz. Einer dieser Gründe liegt darin, dass sich gesprochene und geschriebene Sprache normalerweise in einigen wichtigen Aspekten voneinander unterscheiden. So werden in geschriebener Sprache in der Regel längere und grammatikalisch komplexere Sätze verwendet (z. B. Chafe & Danielewicz, 1987; Weijenberg, 1980; Grundmann, 1975). Außerdem weist gesprochene Sprache eine wesentlich höhere Redundanz auf als geschriebene. Der Inhalt von Gesprochenem wird beispielsweise häufiger mit variierenden Formulierungen wiederholt. Darüber hinaus können nichtsprachliche Aspekte wie Gestik, Mimik und Prosodie die Vermitt-lung des Inhaltes gesprochener Sprache unterstützen, was bei geschriebener Sprache nicht der Fall ist. Kurz gesagt stellt das Verstehen geschriebener Sprache im Allgemeinen höhere kognitive Anforderungen als das Verstehen gesprochener Sprache.
In Bezug auf die Schule ? und hierbei vor allem mit Blick auf den Elementarbereich ? muss darüber hinaus auch bedacht werden, dass der Schriftspracherwerb in einem Alter stattfindet, in dem die Sprachentwicklung generell noch nicht abgeschlossen ist. Während beispielsweise zu Beginn der Grundschulzeit Kinder in der aktiven Textproduktion vor allem temporäre Konjunktionen wie "dann" und "danach" bevorzugen, entwickelt sich das Verständnis für kausale Konjunktionen wie "weil", "deshalb" und "folglich" erst im Laufe der ersten sechs Schuljahre. Auch Rückbezüge innerhalb von Sätzen (z. B. "Lea hat ihrer Freundin versprochen, dass sie heute zu ihr kommt.") werden von Grundschulkindern regelmäßig falsch interpretiert (Oakhill & Garnham, 1988; vgl. auch A. Lenhard, Lenhard & Küspert, 2015, S. 28f). Im ELFE Leseverständnistest wird diesem Umstand dadurch Rechnung getragen, dass im Satzverständnisteil genau solche neuralgischen Punkte der lokalen Kohärenzbildung in den Aufgaben aufgegriffen werden.
Prozesse auf Textebene
Satzübergreifende Informationsintegration
Auf der nächsthöheren Ebene des Leseverständnisses - dem Textverständnis - müssen Informationen, die bei der Analyse einzelner Sätze gewonnen wurden, integriert und zu einem Gesamtbild zusammengesetzt werden (Klicpera & Gasteiger-Klicpera, 1995, S. 136; W. Lenhard, 2013, Kap. 2.1.1). Weiter oben haben wir bereits beschrieben, dass Buchstaben in Wörtern und Wörter in Sätzen nicht isoliert nebeneinanderstehen. Genauso stehen auch Sätze innerhalb von Texten nicht isoliert nebeneinander. Vielmehr werden sie durch sog. Kohäsionsmittel miteinander verknüpft (Christmann & Groeben, 1999). Es gibt viele verschiedene Kohäsionsmittel. Einige von ihnen spielen bereits auf Satzebene eine Rolle, z. B. Konjunktionen wie "danach" und "deshalb". Auch rhetorische Stilmittel können als Kohäsionsmittel fungieren, wie z. B.
- Lexemrekurrenz (d. h. die Wiederaufnahme von Wörtern; z. B. "Mutter ist in Pommerland. Pommerland ist abgebrannt." -> Mutter befindet sich in einem abgebrannten Land.)
- Kataphern (d. h. Vorverweise; z. B. "Falls sie die Wahl gewonnen hätte, wäre das ein Novum in der Geschichte der USA gewesen. Die Rede ist von Hillary Clinton.")
- Anaphern (d. h. Rückverweise; z. B. "Das ist Frau Schmidt. Sie ist die neue Biologielehrerin.")
- Ellipsen (d. h. Auslassungen; z. B. "Ich habe Lust auf Pizza!", "Ich (habe) auch (Lust auf Pizza)!")
Mentale Modelle
Während Worterkennung, syntaktisches Parsing von Sätzen, Propositionsbildung und die Verknüpfung von Sätzen als hierarchieniedere Prozesse bezeichnet werden, subsumiert man Prozesse innerhalb größerer Texteinheiten unter dem Begriff hierarchiehohe Prozesse (vgl. Richter & Christmann, 2002). Damit dieser Begriff nicht falsch interpretiert wird, sei an dieser Stelle allerdings explizit darauf verwiesen, dass hierarchiehohe Prozesse beim Lesen nicht unbedingt eine größere Rolle spielen als hierarchieniedere. Vielmehr müssen ständig alle Prozesse miteinander interagieren, d. h. alle Prozesse müssen funktionieren, damit das Gelesene verstanden wird. Allerdings handelt es sich bei hierarchiehohen Prozessen in der Regel tatsächlich um komplexere Prozesse, da z. B. mehr Material verarbeitet und ein höheres Abstraktionsniveau erreicht werden muss.
Beim Lesen ganzer Texte müssen - analog zum Satzverständnis - die Propositionen (d. h. die Bedeutungen, die den einzelnen Sätzen entnommen wurden) über den Text oder zumindest über Textabschnitte hinweg miteinander verknüpft werden. Die so generierte Bedeutungsstruktur wird anschließend verdichtet und in ein mentales Abbild, ein sogenanntes mentales Modell oder Situationsmodell, überführt, das von der konkreten Wort- oder Satzfolge des Textes unabhängig ist. Das sogenannte Model of Discourse Comprehension nach van Dijk und Kintsch bzw. das später weiterentwickelte Construction-Integration Model (Kintsch & van Dijk, 1978; van Dijk & Kintsch, 1983; Kintsch, 1998) fasst diesen Vorgang als zweistufigen Prozess auf:
- Im ersten Schritt - dem Konstruktionsprozess - werden, wie im Abschnitt "Prozesse auf Satzebene" beschrieben, die Propositionen der Sätze extrahiert. Durch Aktivierung bereits vorhandener Wissensknoten im Langzeitgedächtnis und das Ziehen lokaler Schlussfolgerungen (Inferenzen) werden diese Propositionen miteinander in Beziehung gesetzt. Hierdurch wird die Struktur durch Inhalte angereichert, die über den eigentlichen Textinhalt hinausgehen. Je reichhaltiger das Vorwissen ist, desto leichter fällt es, Bezüge zwischen den Propositionen herzustellen, desto eher können Inferenzen gezogen werden und desto stabiler ist die mentale Repräsentation des Textinhaltes.
- Beim Konstruktionsprozess werden auch unzutreffende Bezüge hergestellt und irrelevante Informationen extrahiert. Die Struktur des entstandenen Netzwerks ist noch ungeordnet und die Beziehungen der Propositionen labil. In der Integrationsphase werden diese Probleme behoben und das Netz wird in eine stabile, kohärente Form übergeführt. Es entsteht eine einheitliche Bedeutungsrepräsentation des Textes, das Situationsmodell. Diese mentale Repräsentation des Textinhaltes ist zumindest teilweise unabhängig von der eigentlichen Textoberfläche, d. h. es müssen nicht mehr zwangsläufig die ursprünglichen Wörter und deren Reihenfolge memoriert werden. Gleichzeitig enthält sie Assoziationen und Schlussfolgerungen, die über den Text hinausgehen.
Auch die Überprüfung des eigenen Verständnisprozesses ist für das verstehende Lesen äußerst bedeutsam. Es handelt sich hierbei um eine metalinguistische Fähigkeit, die sich erst im Laufe der Jahre ausbildet. Leseanfänger haben damit also meist noch gravierende Probleme. So scheitern Erstklässler in der Regel daran, selbst gravierende logische Fehler in Texten zu entdecken. Drittklässler bemerken zwar, dass Inkonsistenzen vorhanden waren, können jedoch oft nicht genau verbalisieren, welche Fehler genau im Text aufgetreten sind (Oakhill & Garnham, 1988, S. 115 f.).
Schlussfolgerndes Lesen
Eine Fähigkeit, die eng mit mentalen Modellen in Verbindung steht, ist das bereits angesprochene schlussfolgernde Lesen. In puncto Leseverständnis wird der Begriff der Inferenz nicht ganz so streng interpretiert wie in der Logik, sondern eher im Sinne von "zwischen oder hinter den Zeilen lesen" verstanden (Klicpera & Gasteiger-Klicpera, 1995, S. 138). Es geht also darum, Informationen von der wortwörtlichen Realisation zu abstrahieren und verschiedene Sätze so miteinander in Verbindung zu setzen, dass ein über den Text hinausreichendes mentales Modell des Textes entsteht. Betrachtet man das Beispiel "Anna versuchte, aus dem schönen Stoff ein Kleid zu machen. Die Schere war stumpf und es bereitete ihr große Mühe.", so ist dem Leser sofort klar, dass Anna versucht, mit der Schere aus dem Stoff Teile auszuschneiden. Damit sich dieses Bild vor dem geistigen Auge entfaltet, müssen allerdings verschiedene nicht triviale und auch logisch nicht unbedingt zwingende Schlüsse gezogen werden. Zum einen ist es erforderlich, die Begriffe Schere, Kleid und Stoff in eine handlungsrelevante Beziehung miteinander zu setzen. Zum anderen muss das anaphorische Pronomen ihr auf Anna bezogen werden.
Von diesen für das Textverstehen notwendigen Inferenzen sind weiterführende Inferenzen abzugrenzen, die das im Text Ausgeführte einengen, ergänzen oder weiterführen. Der Satz "Der Kellner rutschte auf dem frisch gewischten Boden aus und das teure Geschirr fiel zu Boden" (Klicpera & Gasteiger-Klicpera, 1995, S. 138) wird beispielsweise üblicherweise so interpretiert, dass das Geschirr nicht nur auf den Boden fällt, sondern auch zu Bruch geht. Auch dieser Schluss ist logisch nicht zwingend, sondern folgt lediglich einer Heuristik. Im Textverständnistest von ELFE II werden deshalb gezielt Aufgaben dargeboten, bei denen aus den vorhandenen Informationen auf einen Vorgang geschlossen werden muss, der selbst nicht im Text beschrieben ist.
Literatur
| Ahmed, Y., Wagner, R. K. & Lopez, D. (2014). Developmental relations between reading and writing at the word, sentence, and text levels: A latent change score analysis. Journal of Educational Psychology, 106(2), 419-434. DOI: 10.1037/a0035692 |
| Artelt, C., Stanat, P., Schneider, W. & Schiefele, U. (2001). Lesekompetenz: Testkonzeption und Ergebnisse. In J. Baumert, E. Klieme, M. Neubrand, M. Prenzel, U. Schiefele, W. Schneider, P. Stanat, K.-J. Tillmann & M. Weiß (Hrsg.), PISA 2000: Basiskompetenzen von Schülerinnen und Schülern im internationalen Vergleich (S. 69-140). Opladen: Leske + Budrich. |
| Balota, D. A. (1990). The role of meaning in word recognition. In D. A. Balota, G. B. Flores d'Arcais & K. Rayner (Eds.), Comprehension processes in reading (pp. 435-360). Hillsdale, NJ: Lawrence Erlbaum Associates. |
| Brandenburg, J., Klesczewski, J., Fischbach, A., Büttner, G., Grube, D., Mähler, C. & Hasselhorn, M. (2013). Arbeitsgedächtnis bei Kindern mit Minderleistungen in der Schriftsprache: Zur Dissoziation von Lese- und Rechtschreibfertigkeiten und zur Relevanz des IQ-Diskrepanzkriteriums. Lernen und Lernstörungen, 2(3), 147-159. DOI: 10.1024/2235-0977/a000037 |
| Chafe, W. & Jane Danielewicz, J. (1987). Properties of spoken and written language. In R. Horowitz & S. J. Samuels (Eds.), Comprehending Oral and Written Language (pp. 83-113). San Diego: Academic Press. |
| Christmann, U. & Groeben, N. (1999). Psychologie des Lesens. In B. Franzmann & G. Jäger (Hrsg.), Handbuch Lesen (S. 145-223). München: Saur. |
| Coltheart, M. & Rastle, K. (1994). Serial processing in reading aloud: Evidence for dual-route models of reading. Journal of Experimental Psychology: Human Perception and Performance, 20(6), 1197-1211. DOI: 10.1037/0096-1523.20.6.1197 |
| Coltheart, M., Rastle, K., Perry, C., Langdon, R. & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108(1), 204-256. DOI: 10.1037/0033-295X.108.1.204 |
| Cromley, J. G. & Azevedo, R. (2007). Testing and refining the direct and inferential model of reading comprehension. Journal of Educational Psychology, 99(2), 311-325. DOI:10.1037/0022-0663.99.2.311 |
| Dehaene, S. (2010). Lesen. Die größte Erfindung der Menschheit und was dabei in unseren Köpfen passiert. München: Knaus. |
| Denton, C. A., Barth, A. E., Fletcher, J. M., Wexler, J., Vaughn, S., Cirino, P. T. & Francis, D. J. (2011). The relations among oral and silent reading fluency and comprehension in middle school: Implications for identification and instruction of students with reading difficulties. Scientific Studies Of Reading, 15(2), 109-135. DOI: 10.1080/10888431003623546 |
| Ehmke, T. & Jude, N. (2010). Soziale Herkunft und Kompetenzerwerb. In E. Klieme, C. Artelt, J. Hartig, N. Jude, O. Köller, M. Prenzel, W. Schneider & P. Stanat (Hrsg.), PISA 2009. Bilanz nach einem Jahrzehnt (S. 231-254). Münster: Waxmann. |
| Ennemoser, M., Marx, P., Weber, J. & Schneider, W. (2012). Spezifische Vorläuferfertigkeiten der Lesegeschwindigkeit, des Leseverständnisses und des Rechtschreibens: Evidenz aus zwei Längsschnittstudien vom Kindergarten bis zur 4. Klasse. Zeitschrift für Entwicklungspsychologie und Pädagogische Psychologie, 44(2), 53-67. DOI: 10.1026/0049-8637/a000057 |
| Fischbach, A., Preßler, A.-L. & Hasselhorn, M. (2012). Die prognostische Validität der AGTB 5-12 für den Erwerb von Schriftsprache und Mathematik. In M. Hasselhorn & C. Zoelch (Hrsg.), Funktionsdiagnostik des Arbeitsgedächtnisses (S. 37-58). Göttingen: Hogrefe. |
| Fletcher, J. M., Morris, R., Lyon, G. R., Stuebing, K. K., Shaywitz, S. E., Shankweiler, D. P., Katz, L. & Shaywitz, B. A. (1997). Subtypes of dyslexia: An old problem revisited. In B. Blachman (Ed.), Foundations of reading acquisition and dyslexia: implications for early intervention (pp. 115-141). New Jersey: Lawrence Erlbaum Associates. |
| Gabriele, A., Troseth, E., Martohardjono, G. & Otheguy, R. (2009). Emergent literacy skills in bilingual children: Assessing the role of L1 and L2 syntactic comprehension. International Journal of Bilingualism and Bilingual Education, 12(5), 533-547. |
| Gough, P. B. & Tunmer, W. (1986). Decoding, reading and reading disability. Remedial and Special Education, 7(1), 6-10. DOI: 10.1177/074193258600700104 |
| Grimm, H. (1998). Sprachentwicklung - allgemeintheoretisch und differentiell betrachtet. In R. Oerter & L. Montada (Hrsg.), Entwicklungspsychologie. Ein Lehrbuch (4. Auflage, S.705-757). Weinheim: Beltz. |
| Grundmann, H. (1975). Untersuchungen zur mündlichen Rede der Schüler im Deutschunterricht an Wirtschaftsschulen. Göppingen: Alfred Kümmerle. |
| Hattie, J. (2009). Visible learning: A synthesis of over 800 meta-analyses relating to achievement. London: Routledge. |
| Keenan, J. M., Betjemann, R. S. & Olson, R. K. (2008). Reading comprehension tests vary in the skills they assess: Differential dependence on decoding and oral comprehension. Scientific Studies of Reading, 12(3), 281-300. DOI: 10.1080/10888430802132279 |
| Kim, Y. G. & Wagner, R. K. (2015). Text (oral) reading fluency as a construct in reading development: An investigation of its mediating role for children from Grades 1 to 4. Scientific Studies Of Reading, 19(3), 224-242. DOI: 10.1080/10888438.2015.1007375 |
| Kintsch, W. (1998). Comprehension: A Paradigm for Cognition. Cambridge: Cambridge University Press. |
| Kintsch, W. & van Dijk, T. A. (1978). Toward a model of text comprehension and production. Psychological review, 85(5), 363-394. DOI: org/10.1037/0033-295X.85.5.363 |
| Klauda, S. L. & Guthrie, J. T. (2008). Relationships of three components of reading fluency to reading comprehension. Journal of Educational Psychology, 100(2), 310-321. DOI:10.1037/0022-0663.100.2.310 |
| Klicpera, C. & Gasteiger-Klicpera, B. (1995). Psychologie der Lese- und Rechtschreibschwierigkeiten: Entwicklung, Ursachen, Förderung. Weinheim: Beltz. |
| Lenhard, A., Lenhard, W. & Küspert, P. (2015). Lesespiele mit Elfe und Mathis. Göttingen: Hogrefe. |
| Lenhard, W. (2013). Leseverständnis und Lesekompetenz: Grundlagen - Diagnostik - Förderung. Stuttgart: Kohlhammer. |
| Lenhard, W. & Artelt, C. (2009). Komponenten des Leseverständnisses. In W. Lenhard & W. Schneider (Hrsg.), Diagnose und Förderung von Leseverständnis und Lesekompetenz (S. 1-17). Göttingen: Hogrefe. |
| Lenhard, W. & Schneider, W. (2006). Ein Leseverständnistest für Erst- bis Sechstklässler (ELFE 1-6). Göttingen: Hogrefe. |
| Mähler, C. & Schuchardt, K. (2012). Die Bedeutung der Funktionstüchtigkeit des Arbeitsgedächtnisses für die Differentialdiagnostik von Lernstörungen. In M. Hasselhorn & C. Zoelch (Hrsg.), Funktionsdiagnostik des Arbeitsgedächtnisses (S. 59-76). Göttingen: Hogrefe. |
| Martohardjono, G., Otheguy, R. Gabriele, A. de Goeas-Malonne, M., Szupica-Pyrzanowski, M,. Troseth, E., Rivero, S. & Schutzman, Z. (2005). The role of syntax in reading comprehension: A study of bilingual readers. In J. Cohen, K. McAlister, K. Rolstad, & J. MacSwan (Eds.), Proceedings of the 4th International Symposium on Bilingualism (pp. 1522-1544). Somerville, MA: Cascadilla Press. |
| Marx, P. (2007). Lese- und Rechtschreiberwerb. Paderborn: Schöningh. |
| McKeen Cattell, J. (1886). The time it takes to see and name objects. Mind 11(41), 63-65. DOI: 10.1093/mind/os-XI.41.63 |
| Morris, R. D., Stuebing, K. K., Fletcher, J. M., Shaywitz, S. E., Lyon, G. R., Shankweiler, D. P., Katz, L., Francis, D. J. & Shaywitz, B. A. (1998). Subtypes of reading disability: Variability around a phonological core. Educational Psychology, 90(3), 347-373. DOI: 10.1037/0022-0663.90.3.347 |
| Niklas, F. (2015). Die familiäre Lernumwelt und ihre Bedeutung für die kindliche Kompetenzentwicklung. Psychologie in Erziehung und Unterricht, 62(2), 106-120. DOI: 10.2378/peu2015.art11d |
| Oakhill, J. & Garnham, A. (1988). Becoming a skilled reader. Oxford: Blackwell. |
| Perfetti, C.A. (1989). There are generalized abilities and one of them is reading. In L.B. Resnick (Ed.), Knowing, learning, and instruction: Essays in honor of Robert Glaser (pp. 307-335). Hillsdale, NJ: Erlbaum. |
| Richter, T. & Christmann, U. (2002). Lesekompetenz: Prozessebenen und interindividuelle Unterschiede. In N. Groeben & B. Hurrelmann (Hrsg.), Lesekompetenz: Bedingungen, Dimensionen, Funktionen (S. 25-58). Weinheim: Juventa. |
| Sanz, M., Laka, T. & Tanenhaus, M. K. (Eds.). (2013). Language down the garden path. Oxford, UK: Oxford University Press. |
| Schneider, W. (2016). esen und Schreiben lernen: Wie Kinder die Schriftsprache erobern. Heidelberg: Springer-Spektrum. |
| Seymour, P. H. K., Aro, M. & Erskine, J. M. (2003). Foundation literacy acquisition in European orthographies. British Journal of Psychology, 94(2), 143-174. DOI: 10.1348/000712603321661859 |
| Silverman, R. D., Speece, D. L., Harring, J. R. & Ritchey, K. D. (2013). Fluency has a role in the simple view of reading. Scientific Studies of Reading, 17(2), 108-133. DOI: 10.1080/10888438.2011.618153 |
| Stanovich, K., Siegel, L., Gottardo, A., Chiappe, P. & Sidhu, R. (1997). Subtypes of Developmental Dyslexia: Differences in Phonogical and Orthographic Coding. In B. Blachman (Ed.), Foundations of reading acquisition and dyslexia: implications for early intervention (pp. 115-141). Mahwah, NJ: Erlbaum. |
| Van Dijk, T. A. & Kintsch, W. (1983). Strategies of discourse comprehension. New York: Academic Press. |
| Waltzman, D. & Cairns, H. (2000). Grammatical knowledge of third grade good and poor readers. Applied Psycholinguistics, 21(2), 263-284. |
| Weijenberg, J. (1980). Authentizität gesprochener Sprache in Lehrwerken für Deutsch als Fremdsprache. Heidelberg: Groos. |
 |
Überblick |
Untertests |
 |